avalan lets you build, orchestrate, and deploy intelligent AI agents anywhere (locally, on premises, in the cloud) through a unified CLI and SDK that supports any model, multi-modal inputs, and native adapters to leading platforms. With built-in memory, advanced reasoning workflows, and real-time observability, avalan accelerates development from prototype to enterprise-scale AI deployments.
🧠Models
Run any model from a single CLI/SDK—local checkpoints, on-prem clusters, or leading vendor APIs (OpenAI, Anthropic, OpenRouter, Ollama, and many more.).
echo 'Who are you, and who is Leo Messi?' \
| avalan model run "meta-llama/Meta-Llama-3-8B-Instruct" \
--system "You are Aurora, a helpful assistant" \
--max-new-tokens 100 \
--temperature .1 \
--top-p .9 \
--top-k 20
with TextGenerationModel("meta-llama/Meta-Llama-3-8B-Instruct") as lm:
async for token in await lm(
"Who are you, and who is Leo Messi?",
system_prompt = "You are Aurora, a helpful assistant",
settings = GenerationSettings(temperature = 0.1, max_new_tokens = 100, top_p = .9, top_k = 20),
):
print(token, end="", flush=True)
echo 'Who are you, and who is Leo Messi?' \
| avalan model run "ai://$OPENAI_API_KEY@openai/gpt-4o" \
--system "You are Aurora, a helpful assistant" \
--max-new-tokens 100 \
--temperature .1 \
--top-p .9 \
--top-k 20
engine_settings = TransformerEngineSettings(access_token=os.environ("OPENAI_API_KEY"))
with OpenAIModel("gpt-4o", engine_settings) as lm:
async for token in await lm(
"Who are you, and who is Leo Messi?",
system_prompt = "You are Aurora, a helpful assistant",
settings = GenerationSettings(temperature = 0.1, max_new_tokens = 100, top_p = .9, top_k = 20),
):
print(token, end="", flush=True)
echo "[S1] Leo Messi is the greatest football player of all times." \
| avalan model run "nari-labs/Dia-1.6B-0626" \
--modality audio_text_to_speech \
--audio-path example.wav \
--audio-reference-path docs/examples/oprah.wav \
--audio-reference-text "[S1] And then I grew up and had the esteemed honor of meeting her. And wasn't that a surprise. Here was this petite, almost delicate lady who was the personification of grace and goodness."
with TextToSpeechModel("nari-labs/Dia-1.6B-0626") as speech:
generated_path = await speech(
text="[S1] Leo Messi is the greatest football player of all times.",
path="example.wav",
reference_path="docs/examples/oprah.wav",
reference_text=(
"[S1] And then I grew up and had "
"the esteemed honor of meeting "
"her. And wasn't that a "
"surprise. Here was this petite, "
"almost delicate lady who was "
"the personification of grace "
"and goodness."
),
max_new_tokens=5120 # 128 tokens ~= 1 sec.
)
print(f"Speech generated in {generated_path}")
Built-in observability tracks prompts, latency, and rewards, so you can improve behaviour with every run.
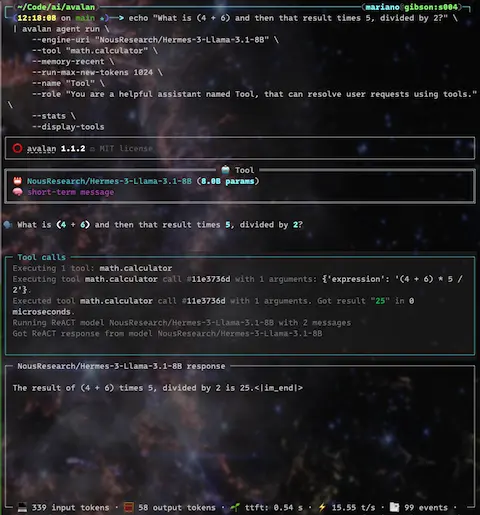
echo "What is (4 + 6) and then that result times 5, divided by 2?" \
| avalan agent run \
--engine-uri "NousResearch/Hermes-3-Llama-3.1-8B" \
--tool "math.calculator" \
--memory-recent \
--run-max-new-tokens 1024 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--stats \
--display-events \
--display-tools \
--conversation
with TextGenerationModel("NousResearch/Hermes-3-Llama-3.1-8B") as lm:
async for token in await lm(
"What is (4 + 6) and then that result times 5, divided by 2?",
system_prompt = "You are a helpful assistant named Tool, that can resolve user requests using tools." ,
settings = GenerationSettings(temperature = 0.9, max_new_tokens = 256),
):
print(token, end="", flush=True)
echo "Hi Tool, based on our previous conversations, what's my name?" \
| avalan agent run \
--engine-uri "NousResearch/Hermes-3-Llama-3.1-8B" \
--tool "memory.message.read" \
--memory-recent \
--memory-permanent-message "postgresql://root:password@localhost/avalan" \
--id "f4fd12f4-25ea-4c81-9514-d31fb4c48128" \
--participant "c67d6ec7-b6ea-40db-bf1a-6de6f9e0bb58" \
--run-max-new-tokens 1024 \
--name "Tool" \
--role "You are a helpful assistant named Tool, that can resolve user requests using tools." \
--stats
with TextGenerationModel("NousResearch/Hermes-3-Llama-3.1-8B") as lm:
async for token in await lm(
"Hi Tool, based on our previous conversations, what's my name?",
system_prompt = "You are a helpful assistant named Tool, that can resolve user requests using tools.",
settings = GenerationSettings(temperature = 0.9, max_new_tokens = 256),
):
print(token, end="", flush=True)
💾Memories
Attach rich semantic history and pluggable knowledge stores with documents, code, or live web pages so agents respond with up-to-date context, not guesswork.
🛠️Tools
Grant agents new powers by wiring in PDF + database lookup and database + graph generation workflows, from internal microservices to public APIs—with fine-grained control over authorization, access, and usage scope.
echo "The attached invoice may match a customer record in the database. Find the matching account and return its account reference ID." \
| avalan model run "ai://env:OPENAI_API_KEY@openai/gpt-5.4" \
--reasoning-effort xhigh \
--tool "database" \
--tool-database-dsn "postgresql+asyncpg://root:password@localhost:5432/invoices_demo" \
--developer "You are a helpful assistant that answers questions using the PostgreSQL database tools. Inspect the schema first, then query precisely. Stay read-only." \
--max-new-tokens 25000 \
--input-file docs/examples/playground/invoice.pdf
import asyncio
from avalan.entities import GenerationSettings, ReasoningEffort
from avalan.model.input import input_files
from avalan.model.nlp.text.generation import TextGenerationModel
from avalan.tool.database import DatabaseToolSet
from avalan.tool.manager import ToolManager
PROMPT = (
"The attached invoice may match a customer record in the database. "
"Find the matching account and return its account reference ID."
)
DEVELOPER = (
"You are a helpful assistant that answers questions using the PostgreSQL "
"database tools. Inspect the schema first, then query precisely. "
"Stay read-only."
)
async def main() -> None:
input_message = input_files(
PROMPT,
["docs/examples/playground/invoice.pdf"],
)
tools = ToolManager(
toolsets=[
DatabaseToolSet(
settings={
"dsn": "postgresql+asyncpg://root:password@localhost:5432/invoices_demo"
}
)
]
)
with TextGenerationModel("ai://env:OPENAI_API_KEY@openai/gpt-5.4") as model:
response = await model(
input_message,
developer_prompt=DEVELOPER,
tool=tools,
settings=GenerationSettings(
max_new_tokens=25000,
reasoning={"effort": ReasoningEffort.XHIGH},
),
)
print(await response.to_str())
asyncio.run(main())
echo 'Generate a monthly bar graph for the total revenue from checks successfully matched to their claims for the organization `Example Legal Group`' | \
avalan agent run \
--engine-uri "ai://env:OPENAI_API_KEY@openai/gpt-5.4" \
--reasoning-effort xhigh \
--tool "database" \
--tool "graph.bar" \
--tool-database-dsn "postgresql+asyncpg://root:password@localhost:5432/example_app" \
--tool-graph-file "./monthly-revenue.png" \
--developer "You are a helpful assistant that answers questions using tools. Inspect the schema first, then query precisely. Stay read-only." \
--run-max-new-tokens 25000 \
--stats \
--display-tools \
--display-events
import asyncio
from uuid import uuid4
from avalan.agent.loader import OrchestratorLoader
from avalan.entities import OrchestratorSettings
from avalan.tool.context import ToolSettingsContext
from avalan.tool.database.settings import DatabaseToolSettings
from avalan.tool.graph_settings import GraphToolSettings
PROMPT = (
"Generate a monthly bar graph for the total revenue from checks "
"successfully matched to their claims for the organization "
"`Example Legal Group`"
)
DEVELOPER = (
"You are a helpful assistant that answers questions using tools. "
"Inspect the schema first, then query precisely.\n"
"Stay read-only."
)
async def main() -> None:
settings = OrchestratorSettings(
agent_id=uuid4(),
uri="ai://env:OPENAI_API_KEY@openai/gpt-5.4",
agent_config={"developer": DEVELOPER},
tools=["database", "graph.bar"],
call_options={
"max_new_tokens": 25000,
"reasoning": {"effort": "xhigh"},
},
memory_recent=True, # CLI default unless --no-session
log_events=True,
)
tool_settings = ToolSettingsContext(
database=DatabaseToolSettings(
dsn="postgresql+asyncpg://root:password@localhost:5432/example_app"
),
graph=GraphToolSettings(file="./monthly-revenue.png"),
)
loader = OrchestratorLoader()
async with await loader.from_settings(settings, tool_settings=tool_settings) as agent:
response = await agent(PROMPT)
print(await response.to_str())
asyncio.run(main())
🌎Connections
Let agents talk. Expose them through your preferred protocol (OpenAI-compatible API, MCP, A2A) or bridge them via MCP tooling to other local or remote agents.
🔀Flows
Orchestrate complex, multi-agent processes with intuitive agent collaboration with flows. Enjoy full end-to-end observability for debugging and performance, and manage task lifecycles to support both human-in-the-loop and fully automated workflows.
🚀Deploy
Deploy your intelligent solution on-premises or to the cloud in minutes. Choose between stateful, long-lasting agents for ongoing services or lightweight,ephemeral intelligent tasks for burst-scale operations.